[rocksDB] rocksDB의 소개와 구조
Updated:
rocksDB란?
RocksDB는 구글의 오픈소스 프로젝트인 LevelDB를 기반으로 페이스북에서 개발한 비정형 데이터 베이스$($NOSQL) 입니다.
NOSQL $($Not Only SQL)이기 때문에 key-value 저장방식을 취하기 때문에 대용량 데이터 처리에 적합하며 특히 LSM $($Log Structured Merge) - Tree 구조이기 때문에 SSD 저장장치에서 높은 성능을 발휘하도록 최적화 되어있습니다.
Embedded $($C++ 라이브러리) 형태로 제공되고 원자 읽기/쓰기를 지원하며 compaction, filtering, format 등과 같은 다양한 알고리즘으로 구성되어 있습니다.
왜 Embedded 형태인가
SSD와 같은 fast storage가 발전함에 따라 어플리케이션과 DB 서버가 분리되있던 전통 방식의 경우
네트워크 오버헤드가 심해지는 문제가 발생하였고 이를 해결하기 위해 어플리케이션 안에 DB를 삽입하는 Embedded 방식이 채택되었습니다.
LSM-tree란?
Log Structured Merge tree
쓰기 처리률을 최적화 시키기 위한 자료구조
- Log-structure
플래쉬 메모리에서 데이터의 수정은 out-place update 방식으로 이루어 집니다.
파일시스템에서 모든 메타데이터의 변경사항은 일관성 유지를 위해 로그에 순차적으로 기록됩니다.
디스크 메타데이터 갱신에 대한 로그를 사용하는 이득은 이들을 직접 디스크 자료 구조에 적용하는 것보다갱신이 더 빠르다는 것 입니다. 이러한 성능 향상은 임의 입출력에비해 순차 입출력이 빠르다는데서 찾을 수 있습니다.
- Merge
오래된 데이터를 지우기 위해 특정 level과 그 하위 level sstable 간의 합병정렬이 이루어 집니다. 때문에 모든 데이터는 정렬된 상태로 저장됩니다.
- Tree
하위 level로 내려 갈수록 넓어지는 트리 형태의 구조로 이루어져 있습니다.

Key-Valuse 인터페이스
Key와 value는 임의의 byte stream으로 이루어져 있습니다. Key, value의 크기에는 제한이 없으며 put, get, iterator(range scan), delete, single delete … 등의 사용자 인터페이스를 통해 key-value값의 연산이 가능합니다.
rocksDB 내부 연산
- Flush
- Compaction
- Snapshot …
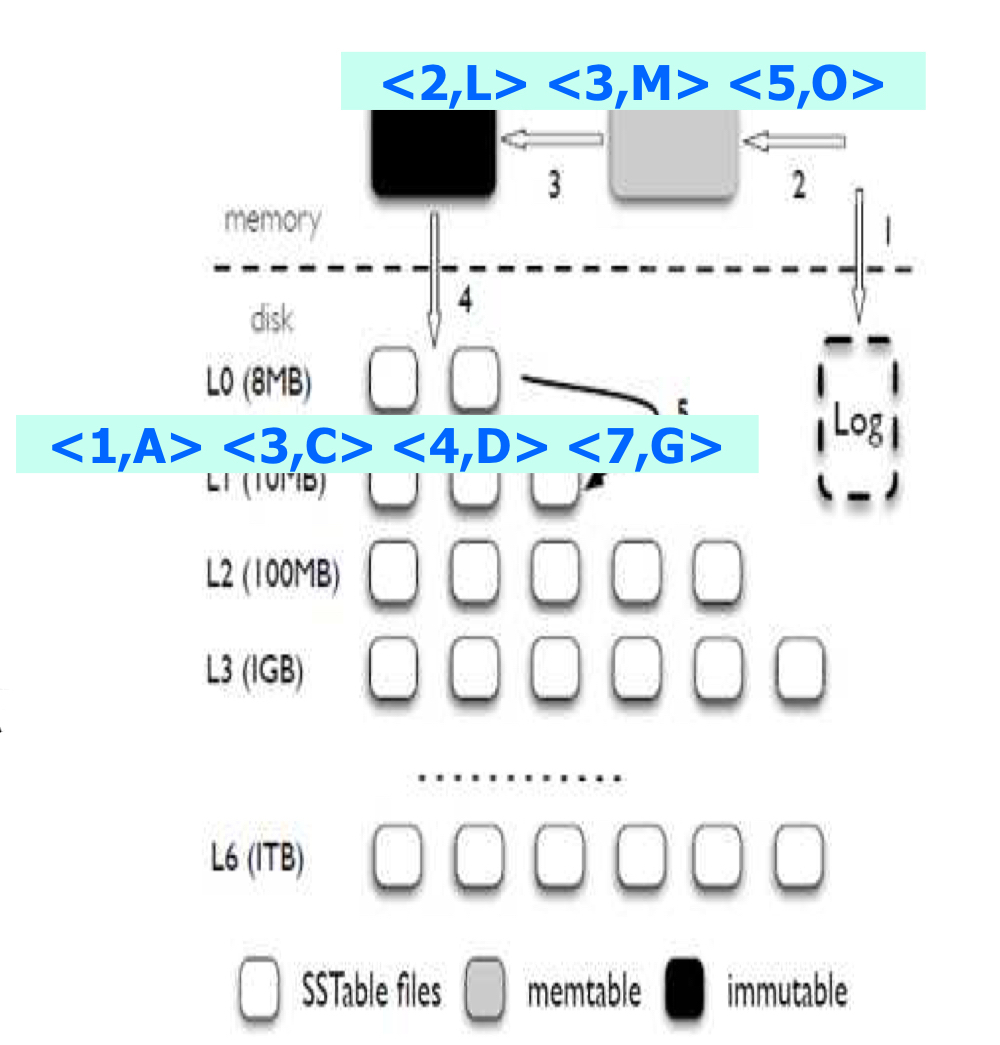
put/get, flush Workload
가정
-
Memtable과 sstable에는 총 4개의 KV$($key-value pair)만 저장가능
-
L0에는 2개의 sstable, Li+1 = Li*2 로 하위 레벨로 내려갈수록 공간이 두배씩 증가
Workload
-
put$($”1”, “A”), put$($”3”, “C”), put$($”4”, “D”), put$($”7”, “G”)
-
Memtable이 가득찼으므로 -> immutable 상태로 변환, 메모리에서 디스크로
flush된다. $($Background에서 수행) -
새로운 memtable이 할당된다. $($Out-place update).
-
put$($”2”, “L”), put$($”3”, “M”), put$($”5”, “O”)
-
get(1), get(2), get(3). 최근 데이터 일수록 상위 level에 존재
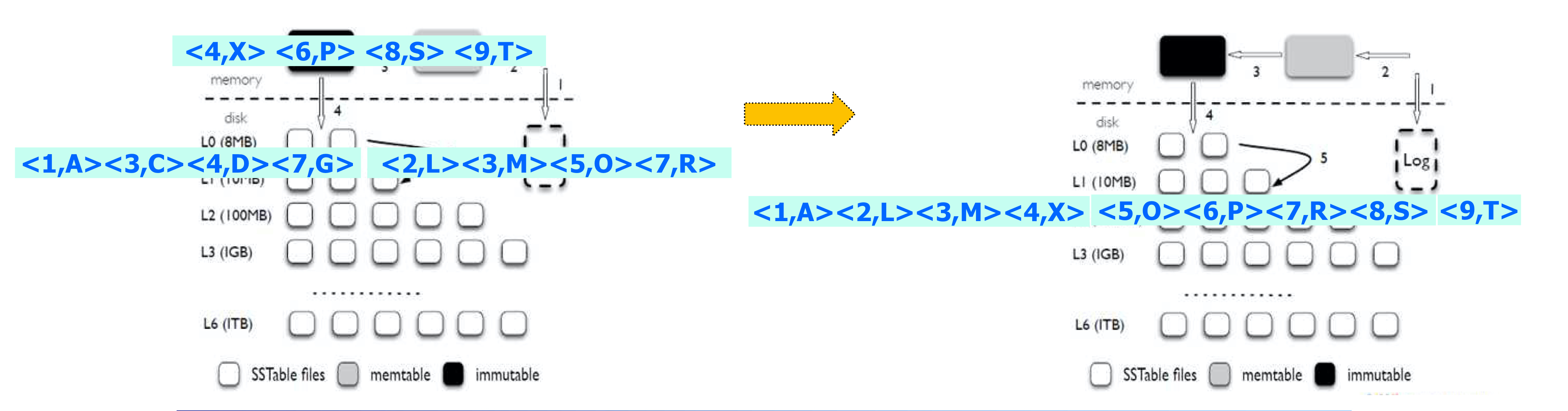
Compaction workload
-
put$($”7”, “R”)
-
Memtable -> immutable. flushed
-
put$($”6”, “P”), put$($”4”, “X”), put$($”8”, “S”), put$($”9”, “T”)
-
Memtable -> immutable. flushed again
-
L0의 두 sstable이 가득차게 된다. ->
Compaction begin
1) Compaction을 진행할 sstable을 선정한다.
2) 중복된 $($overlapped) key값을 갖는 sstable을 읽어 들인다.
3) sstable들의 데이터 간에 합병정렬을 수행한다.
4) 하위 level의 sstable에 compaction 결과값을 쓴다.
L0에는 중복된 key값이 존재할 수 있지만 L1 ~ Lmax 에는 sstable간의 중복된 key값은 존재할 수 없다.
Bloom filter를 통한 데이터 읽기
특정 key값을 get 해오고 싶다면 데이터를 찾기위한 과정은 먼저 memtable에 원하는 데이터가 존재하는지 확인하기 위하여 읽어들이고 그다음 L0의 sstable, 그 아래 level의 sstable을 순서대로 읽어가며 데이터를 찾게 됩니다.
하지만 데이터를 찾을때 마다 이러한 과정을 거치게 된다면 불필요한 read 연산을 반복하게 됩니다.(read amplification)
이때 Bloom filter를 적용하게 되면 데이터가 정렬되있다는 특성을 활용하여 이진탐색을 사용해 sstable에 원하는 key값의 존재여부를 빠르게 파악하는것이 가능합니다.
Reference
rocksDB wiki
단국대학교 소프트웨어학과 최종무 교수님 강의자료
Leave a comment