[Docker 이론] 다중 서버에서의 도커엔진
Updated:
앞서 [Docker 이론] 가상화와 컨테이너의 등장배경 포스트에선 단일 서버 내에서의 단일 도커엔진에 대해서 알아보았다.
이번 포스트에서는 여러개의 서버의 도커 엔진에 대해 알아보도록 하겠다.
만약 기존에 운영하던 호스트 머신에 컨테이너가 너무 많아져서 자원이 부족해 새로운 컨테이너를 추가하지 못하는 상황이 발생했다고 가정해 보자. 이를 어떻게 해결할 수 있을까?
1. Scale Up
Scale Up은 매우 성능이 좋은 새로운 서버를 마련하는 방법을 말한다.
하지만 이는 그닥 권장되는 해결책이 아니다.
자원이 필요할때 마다 새로운 서버를 사야하는 작업이 번거로우며 막상 좋은 서버를 샀는데 그만큼의 자원을 전부 활용하지 못할 수도 있기 때문이다.
2. Scale Out
자원을 늘리는 방법으로 가장 많이 사용되는 방법인 Scale Out은, 여러 대의 서버를 클러스터로 만들어 자원을 병렬로 확장하는것이다.
다시 말해, 작은 크기의 서버를 필요에 따라 하나의 클러스터로 묶어서 서버를 확장시켜 나가는 것이다. 이 방법은 자원이 제대로 활용되지 못할 시에는 자원을 다시 줄일 수도 있다.
하지만 이 방법의 경우 여러대의 서버를 하나의 자원풀로 만드는 방법이 복잡하다는 단점이 있다. 클러스터를 도입하게 될 경우, 스케줄러, 로드밸런서 등의 고가용성 보장을 처리해 주어야 하며 새로운 서버나 컨테이너가 추가될때 발견하는 작업도 처리해 주어야 하는 번거롭고 어려운 절차를 거쳐야 한다.
3. 도커 스웜

이미지 출처 - https://subicura.com/2017/02/25/container-orchestration-with-docker-swarm.html
스웜모드를 사용하는 가장 큰 이유는 서비스의 확장 및 관리를 편하게 하기 위해서 이다.
도커 스웜에서 지원하는 스웜모드는 필요에 따라 유동적으로 컨테이너 수를 조절할 수 있고 컨테이너로의 연결을 분산하는 로드밸런싱 기능 또한 자체적으로 지원하고 있다.
Scale Out 또한 지원하지만 기존의 Scale Out과는 다르게 개발자가 직접 인스턴스를 늘리거나 줄이는 작업을 해야한다.
스웜은 도커 엔진 자체에 내장되어있다.

이미지 출처 - https://www.docker.com/blog/introducing-docker-engine-18-09/
3-1. 스웜 모드의 구조

이미지 출처 - https://docs.google.com/document/d/1x9EHhj_cwuZGY0W6aPXlETUZ5PIJ4czXXtXA-rSu9ts/mobilebasic
스웜 모드는 매니저 노드와 워커 노드로 구성 되어있다.
워커 노드에서는 실제로 컨테이너가 생성되고 관리되는 도커 서버이고 매니저 노드는 이러한 워커노드의 기능을 기본적으로 수행하면서 워커 노드를 관리하는 기능또한 수행한다.
매니저 노드는 매니저 노드의 부하를 분산하고 특정 매니지 노드가 다운되는 경우를 대비하여 운영환경에서 다중화 하는것이 좋다.
그렇다면 스웜 모드에서 클러스터는 어떻게 구축하는지 AWS EC2 인스턴스를 예로 들어 설명해 보겠다.
3-2. 스웜 모드에서의 클러스터 구축
4개의 EC2 인스턴스를 갖고 하나의 매니저 노드와 3개의 워커 노드로 이루어진 클러스터를 구축해 본다고 가정하자.
docker swarm init 명령어를 통해 매니저 노드를 설정해 줄 수 있다.
docker swarm join 을 통해 워커 노드를 매니저 노드에 할당해 줄 수 있다.
이렇게 하나의 클러스터 단위가 생성이되고 클러스터 안에서 서비스를 실행할 수 있게 되었다.
여기서 서비스란?
일반적으로 도커 명령어를 실행하게 되면 명령어의 제어 단위는 컨테이너이다.
다르게 말해서 이는 도커 클라이언트가 제어하는 것이 컨테이너라는 것과 같은 말이다.
하지만 도커 스웜에서 명령어의 제어 단위는 컨테이너가 아닌 서비스이다.
서비스란 같은 이미지에서 생성된 컨테이너의 집합을 의미한다.
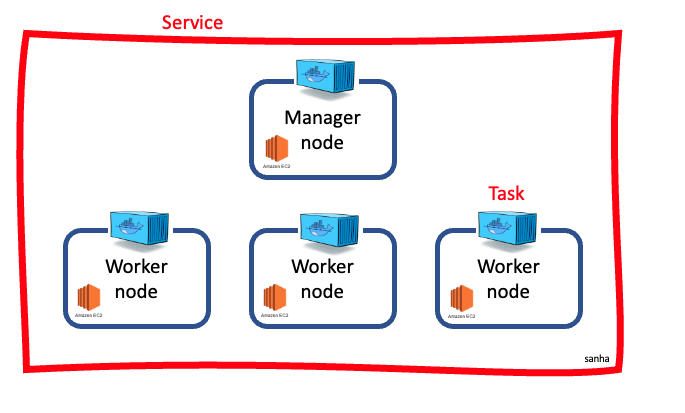
서비스를 제어하게 되면 해당 서비스안의 컨테이너들은 모두 같은 명령이 수행된다.
이때 서비스 내의 컨테이너를 테스크라고 부른다.
서비스 설정을 통해 노드에 테스크를 분산해서 생성하게 되는데, 이때 함께 생성된 테스크를 레플리카라고 한다.
이때 서비스에 설정된 레플리카의 수만큼 테스크가 스웜 클러스트 내에 존재해야만 한다는 조건이 붙게된다.
스웜은 서비스의 각 테스크에 대한 상태를 계속 주의하고 있다가 하나의 노드에 장애가 발생하게 되면 위의 조건이 발동하게 된다.
노드가 다운되어$($장애 노드내의 레플리카도 같이 죽게된다.) 조건에 맞는 레플리카 수만큼 서비스 내에 레플리카가 존재하지 않게 된다면 다른 노드에 새로운 테스크 레플리카를 생성해서 조건을 만족시켜 주게 된다.
$($단, 매니저 노드가 다운된다면 클러스터 자체가 사라지게 된다.)
앞의 과정을 다시 한번 정리해 보자면 먼저 하나의 프로젝트 단위를 클러스터 내에 묶었고 프로젝트를 구동하기 위해서 컨테이너를 기반으로 테스크가 생성되었다.
매번 이러한 과정을 명령어를 통해 수행하며 컨테이너를 생성할 수 있지만 상당히 번거로운 작업이 아닐수 없다.
컨테이너의 생성을 편리하게 하기 위해 등장한 방법이 바로 도커 컴포즈이다.
4. 도커 컴포즈

도커 컴포즈는 여러개의 컨테이너를 하나의 서비스로 정의하고 실행한다.
도커 컴포즈 또한 스웜모드와 마찬가지로 yml파일에 정의된 서비스의 컨테이너 수를 유동적으로 조절할 수 있고 서비스의 디스커버리도 자동으로 이루어진다.
도커 컴포즈는 컨테이너의 설정이 정의된 yml 파일을 읽은 다음 도커 엔진을 통해 컨테이너를 생성한다.
도커 컴포즈를 위한 yml 파일을 작성하고 난 후, docker-compose 명령어를 통해 컨테이너를 생성 할 수 있다.
4-1. 도커 컴포즈의 구조
도커 컴포즈는 관례상 yml 파일이 저장된 디렉토리 이름을 프로젝트 이름으로 설정하게 된다.
하나의 프로젝트는 여러개의 서비스로 이루어지고 하나의 서비스에는 여러개의 컨테이너가 존재할 수 있다.
이때 각각의 컨테이너에는 번호가 주어지며 서비스 내에서는 이 번호를 가지고 컨테이너를 구별하게 된다.
Leave a comment